Chapter 4 More R
In this chapter of this companion website to the Insights book we outline some of the parts of R and RStudio that we mentioned in the book, but did not then feel the need to cover. If you would like more details below, some examples, or other topics covered, please let us know.
4.1 RStudio Project setup
In the Insights book we strongly recommend using the Projects that are built into RStudio. And we strongly recommend organising the folders and files on your computer into projects. Here are the ready made empty folders and Project files mentioned in Insights (the book) section Projects in RStudio.
4.2 Base/classic and tidyverse comparison
Insights teaches you to use R with the tidyverse add-on packages and functions. Not everyone uses R with these functions, however, so it can be useful to know a little about the classic (older but still often used) ways to use R. One instance in which you might benefit from this is if you have access to scripts written some times ago, or are working with seasoned R veterans who do not use the tidyverse.
The table in Figure 4.1 below compares common data manipulation methods using the classic way (base R) and the modern way, with functions in the dplyr package. The placement of the comma, when using [ ], is quite important and subtle. The help files for subset(), order(), aggregate(), and tapply() are worth consulting should you run into these functions.
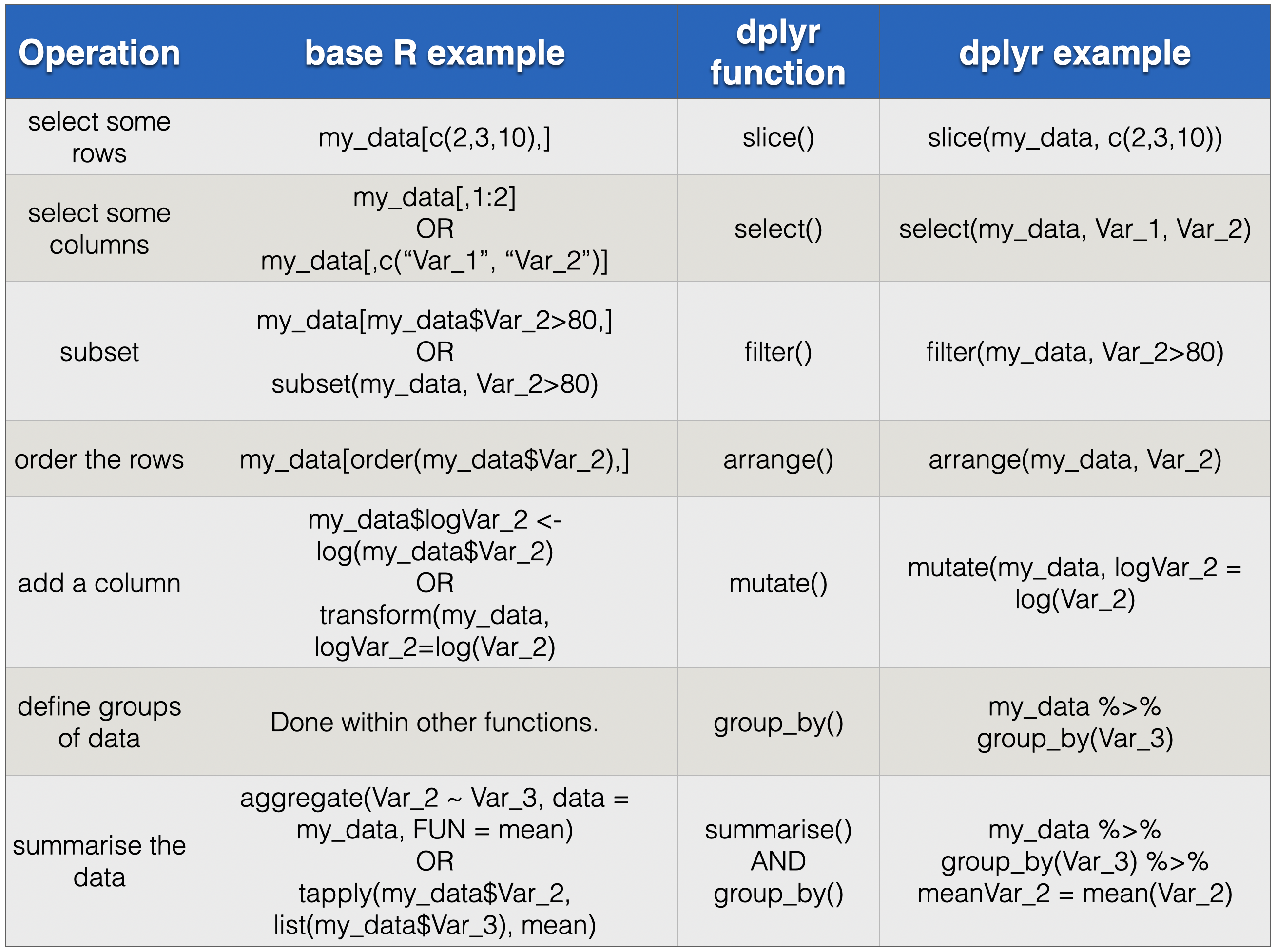
FIGURE 4.1: Comparison of classic/base R methods and dplyr methods for common operations.
Using dplyr, we use the functions select(), slice(), and filter() to get subsets of data frames. The classic method for doing this often involves something called indexing, and this is accomplished with square brackets and a comma, with the rows we want before the comma and the columns/variables we want after the comma: something like my_data[rows, columns]. There are lots of ways of specifying the rows and columns, including by number, name, or logical operator. It’s very flexible, quick, and convenient in many cases. Selecting rows can also be done with the subset() base R function, which actually possesses the combined functionality of filter() and select() from dplyr. Ordering rows or columns can be achieved by a combination of indexing and the base R order() function.
Adding a new variable, which might be some transformation of existing ones, is also very similar between base R, using the transform() function, and dplyr, using the mutate() function. People often add columns by using a dollar sign followed by the new variable, for example my_data$new_variable <- my_data$old_variable.
The classic and still useful methods for getting information about groups of data use functions like aggregate() and tapply() – both of these were covered in detail in the previous edition of this book. These functions have separate arguments that specify the groups and the summary statistics. In dplyr the groups are specified by the group_by() function and the summary statistics by summarise().
4.3 Multiple graphs in one figure
We showed how to make multiple facets in one graph, but what about if we’d like to arrange multiple different ggplot graphs in one figure. There are a number of approaches to doing this. Our favourite at the moment is with the patchwork add-on package. Here is what the authors write: “The goal of patchwork is to make it ridiculously simple to combine separate ggplots into the same graphic.” Read and learn here more:
4.4 Factors
Variables that contain categories can, if one likes, be made factor type variables in R. This is useful when visualizing data, especially when we want to control the order in which categories are given in a figure. We describe this in detail in the Workflow Demonstration on prey diversity and predator population stability in the section Make the prey_composition variable a factor with specific order.
Please note that it used to be that commonly used data import functions in R would automatically convert character variables to factors… so we just about always needed to deal with factors. But R changed, so now this doesn’t happen, and we are left with character variables. And we need to make variables factors if we want them to be so. As mentioned above, we mostly do this when we want to control the presentation order of categories in figures.
4.5 Other pipes
This is likely not so important, so only pay attention if you really have little better to do. There are a number of other pipes (in addition to %>%). Take a look here for an explaination https://thewoodpeckr.wordpress.com/2020/02/10/upping-your-pipe-game/
4.6 Simulating data
If you’d like to simulate data, then function in the tidyverse provide a convenient general infrastructure, that can take the sting out of some of the more tedious housekeeping that one might otherwise need to take considerable care over. Have a look at this website https://www.r-bloggers.com/the-birthday-paradox-puzzle-tidy-simulation-in-r/. It provides a nice introduction to simulating in R with the tidyverse. It does, however, use a couple of functions (such as crossing and map) that we don’t use in the book, and you may need to read up about these separately.
4.7 Avoiding “loops”
Anyone with a programming background will think about using loops to repeat tasks. We can (and often do) make loops in R, but we do so much less frequently than we used to, at least when we’re analysing data. Instead, we now use the group_by function to repeat tasks on groups of a dataset. An example of us doing this is in the fish dietary restriction workflow demonstration, where we calculate the growth rate of each of the 300 fish, by doing a linear regression on each fish and keeping the slope of the relationship. We accomplish this by using a group_by to work on each fish separately, piped into a do function, which contains the regression, followed by a little tidying (with the tidy function of the **broom** package) and anunnest`. It may sound complex, and even look so. But just remember that we just did 300 regressions (one for each fish) and got a nice tidy dataset with the slope of the regression line of each fish (with six lines of code).
Bottom line. Try to avoid loops when working with data. But don’t think to avoid them forever… they can be very useful.
4.8 Syntax highlighting
From the book: “Throughout this book you will see that different parts of our R commands have different colours. We could here explain all the different parts and different colours. But then we would have to explain the grammar and syntax in more detail than we feel is currently useful for you. In case you wonder, however, please look on the Insights companion website (http://insightsfromdata.io).”
Now we’re writing this companion web site we still don’t see a great need to explain every colour and the corresponding type of R code. In any case, we can easily change the colours, so it would not make much sense to list the colours. If you’re really interested in digging down into this, take a look at the code for the highlight R package.
4.9 Summarise more than one variable
In the book and on this website we only summarise one column at a time. But we can do more than one. Please take a look at this webpage of the dplyr package, which details how to summarise multiple columns.